Основы программирования — второй семестр 08-09; Михалкович С.С.; II часть
Содержание
Указатели
Адрес
Оперативная память состоит из последовательный ячеек. Каждая ячейка имеет номер, называемый адресом.
В 32-битных системах можно адресовать 232 байт (<math>\approx \;</math> 4Гб) памяти, в 64-битных — 2 64 соответственно.
Переменная (или константа), хранящая адрес, называется указателем.
Для чего нужны указатели
Указатели повышают гибкость доступа к данным:
- Вместо самих данных можно хранить указатель на них. Это позволяет хранить данные в одном экземпляре и множество указателей на эти данные. Через разные указатели эти данные можно обновлять (пример — корпоративная БД).
- Указателю можно присвоить адрес другого объекта (вместо старого появился новый телефонный справочник).
- С помощью указателей можно создавать сложные структуры данных.
Подробнее об указателях
Указатели делятся на:
- Типизированные (указывают на объект некоторого типа)
Имеют тип: ^<тип>
Пример. ^integer — указатель на integer - Бестиповые (хранят адрес ячейки памяти неизвестного типа)
Преимущество: могут хранить что угодно
Имеют тип: pointer
Пример кода.
var
i: integer := 5;
r: real := 6.14;
pi: ^integer;
pr: ^real;
begin
pi := @i;
pr := @r;
pi := @r; // ОШИБКА компиляции
end.@ — унарная операция взятия адреса <xh4>Операция разадресации (разыменования)</xh4>
var
i: integer := 5;
pi: ^integer;
begin
pi := @i;
pi^ := 8 - pi^;
writeln(i); // 3
end.^ — операция разыменования
pi^ — то, на что указывает pi, т.е. другое имя i или ссылка на i.
Тут надо вспомнить определение ссылки:
Ссылка — другое имя объекта.
<xh4>Нулевой указатель</xh4>
Все глобальные неинициализированные указатели хранят специальное значение nil, что говорит о том, что они никуда не указывают.
Указатель, хранящий значение nil называется нулевым.
var
pi: ^integer; //указатель pi хранит значение nil
i: integer;
begin
pi := @i; //pi хранит адрес переменной i
pi := nil; //pi снова никуда не указывает
pi^ := 7; //ОШИБКА времени выполнения:
//попытка разыменовать нулевой указательПопытка разыменовать нулевой указатель приводит к ошибке времени выполнения. <xh4>Бестиповые указатели</xh4>
var
p: pointer;
i: integer;
begin
p := @i;
end.Бестиповому указателю можно присвоить адрес переменной любого типа, т.е. бестиповой указатель совместим по присваиванию с любым типовым указателем.
Попытка разыменовать бестиповой указатель приводит к ошибке компиляции. Т.е. он может только хранить адреса.
Оказывается, любой типизированный указатель совместим по присваиванию с бестиповым, т.е. следующий код верен:
var
pi: ^integer;
i: integer;
p: pointer;
begin
p := @i;
pi := p;
pi^ += 2;
end.Вопрос. Нельзя ли интерпретировать память, на которую указывает p, как принадлежащую к определенному типу?
Ответ — да, можно. Вот как это сделать:
type
pinteger = ^integer;
var
i, j: integer;
p: pointer;
begin
p := @i;
pinteger(p)^ := 7; //используем явное приведение типа
writeln(i); // 7
end.Запись
<тип>( <переменная> )
показывает, что используется явное приведение типов.
Внимание! Неконтролируемая ошибка!
type
pinteger = ^integer;
var
i, j: integer;
p: pointer;
begin
p := @i;
preal(p)^ := 3.14; //ОШИБКА!
end.Область памяти, на которую указывает p трактуется как область, хранящее вещественное число (8 байт), и потому константа 3.14 записывается в эти 8 байт. Однако, переменная i занимает только 4 байта, поэтому затираются еще 4 соседних байта (в данном случае они принадлежат переменной j).
Доступ к памяти, имеющей другое внутреннее представление
type
Rec = record
b1, b2, b3, b4, b5, b6, b7, b8: byte;
end;
PRecord = ^Rec;
var
r: real := 3.1415;
prec: ^Rec;
begin
var temp : pointer := @r;
prec := PRecord(temp); //Явное приведение типа
writeln(prec^.b1, ' ', prec^.b2, ' ', {..., } prec^.b8);
end.Замечание. Важно, что типы real и Rec имеют один размер.
Динамическая память
Особенности динамической памяти
Память, принадлежащая программе, делится на:
- Статическую
(память, занимаемая глобальными переменными и константами) - Автоматическую
(память, занимаемая локальными данными, т.е. стек программы) - Динамическую
(память, выделяемая программе по специальному запросу)
В дополнение к статической и автоматической памяти, которые фиксированы после запуска программы, программа может получать нефиксированное количество динамической памяти. Ограничения на объём выделяемой динамической памяти связаны лишь с настройками операционной системы и объемом оперативной памяти компьютера.
Основная проблема — явно выделенную динамическую память необходимо возвращать, иначе не хватит памяти другим программам.
Для явного выделения и освобождения динамической памяти используются процедуры:
- New
- Dispose
var
p: pinteger; //p никуда не указывает
begin
New(p); //в динамической памяти выделяется ячейка
//размером под один integer, и
//p начинает указывать на эту ячейку
p^ := 3;
Dispose(p); //возвращает динамическую память,
//контролируемую указателем p, назад ОС
end.По окончании работы программы, вся затребованная программой динамическая память возвращается ОС.
Но лучше освобождать динамическую память явно! Иначе в процессе работы программы она может занимать большие объёмы (ещё не освобождённой) памяти, что вредит общей производительности системы.
Ошибки при работе с динамической памятью
1.var p: pinteger;
begin
p^ := 5; //ОШИБКА
end.Ошибка разыменования нулевого указателя (попытка использовать невыделенную динамическую память).
2.var p: pinteger;
begin
New(p);
New(p); //ОШИБКА
end.Утечка памяти (память, которая выделилась в результате первого вызова New(p), принадлежит программе, но не контролируется никаким указателем.
3.var p: pinteger;
begin
for var i:=1 to 1000000 do
New(p); //ОШИБКА
end.Out of Memory (очень большие утечки памяти, в результате которых динамическая память может «исчерпаться»).
4.var p: pinteger;
begin
New(p);
p^ := 5;
Dispose(p);
p^ := 7; //ОШИБКА
end.После вызова Dispose(p), p называют висячим указателем (т.к. он указывает на недоступную более область памяти).
Неявные указатели в языке Pascal
- procedure p(var i: integer)
Для параметра-переменной при вызове на стек кладется не сама переменная, а указатель на неё. - var pp: procedure(i: integer)
Для хранения процедурной переменной используется ячейка памяти, являющаяся указателем. - var a: array of real;
Переменная типа динамический массив является указателем на данные массива, хранящиеся в динамической памяти.
Введение в классы
От записей к классам
Рассмотрим запись студент:
type
Student = record
name: string;
age: integer;
procedure Init(n: string; a: integer);
begin
name := n;
age := a;
end;
procedure Print;
begin
writelnFormat('Имя: {0} Возраст: {1}',
name, age);
end;
end;
var
s: student;
begin
s.Init('Иванов', 18);
end.Когда мы описываем переменную типа Student, она кладется на программный стек.
А вот так выглядит класс Student:
type
Student = class
name: string;
age: integer;
constructor Create(n: string; a: integer);
begin
name := n;
age := a;
end;
procedure Print;
begin
writelnFormat('Имя: {0} Возраст: {1}',
name, age);
end;
end;
var
s: student;
begin
s := New Student('Иванов', 18);
end.Переменная типа класс является указателем. Для выделения динамической памяти под объект класса Student используется вызов специального метода, называемого конструктором (New Student(<имя>, <возраст>)).
Лекция 4
Шаблоны классов
type
Point<T> = class
x, y: T;
constructor(_x, _y: T);
begin
x := _x;
y := _y;
end;
end;
begin
var p1 : Point<real>;
var p2 : Point<integer>;
p1 := new Point<real>(2.3, 5.7);
p2 := new Point<integer>(2, 7);
p1.x := 2;
p2.x := 1.5; // ошибка компиляции, т.к.
// тип поля x объекта класса Point<integer> (integer)
// не совместим по присваиваиванию с вещественным типом real
//можем пользоваться автоопределением типов:
var p3 := new Point<real>(3.14, 7.9);
end.Тип Point<T> называют обощенным типом.
Теперь рассмотрим присваивание объектов класса:
var p11 := new Point<real>(0, 1.5);
var p12 := new Point<real>(2.3, 5);
p11 := p12; // происходит присваивание ссылок:
// p11 теперь указывает на тот же объект, что и p12;
// область памяти, на которую до этого указывал p11 более недоступна
var p2 := new Point<integer>(5, 7);
p11 := p2; // ошибка
// типы объектов не совпадаютПри присваивании же друг другу записей, происходит копирование самих записей.
Сборка мусора
(Garbage collection)
Мусор — любые ненужные объекты.
Под ненужными понимаются объекты, которые занимают память, но недоступны в программе.
Сборка мусора — процесс освобождения памяти, занятой ненужными объектами.
Обычно, сборка мусора запускается при нехватке места в памяти. Это позволяет не заботиться об утечках памяти, т.к. все выделенное — освободится. (При этом, от всех остальных ошибок мы не застрахованы!!!)
Главный недостаток механизма сборки мусора — во время сборки выполнение программы приостанавливается.
Динамические структуры данных
Введение
Сейчас структуры данных занимают в программировании все более важную позицию.
Мы уже знаем такие структуры, как:
- массивы (подразумеваем статические)
- записи
Их основная проблема — фиксированный размер, определяемый на этапе компиляции.
Решением проблемы являются динамические структуры данных. Они строятся из узлов, которые, в свою очередь, состоят из данных и полей связи.
Рассмотрим такой пример:
type
Node<DataType> = class
data: DataType;
next: Node<DataType>;
constructor (d: DataType; n: Node<DataType>);
begin
data := d;
next := n;
end;
end;
begin
var p := new Node<char>('!', nil); // под объект класса Node<char> выделилась динамическая память;
// p начала указывать на эту динамическую память
end.Виды списков
- Линейный односвязный список

- Циклический односвязный список

- Двусвязный линейный список

- Циклический двусвязный список
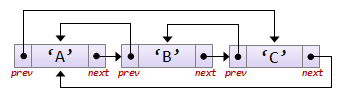



Односвязные линейные списки
type
Node<DataType> = class
data: DataType;
next: Node<DataType>;
constructor (d: DataType; n: Node<DataType>);
begin
data := d;
next := n;
end;
end;
begin
{Пусть у нас есть указатель на начало списка:}
var head: Node<char>;
// инициализация head<xh4>Стандартные операции с односвязными линейными списками</xh4>
- Вставка элемента в начало

head := new Node<char>('A', head);При многократной вставке в начало элементы располагаются в обратном порядке.
- Удаление элемента из начала

head := head.next;Если изначально список пуст, произойдет ошибка «попытка разыменования нулевого указателя». Эту ситуацию надо предусмотреть:
if head <> nil then
head := head.next;- Вставка элемента после текущего

cur.next := new Node<char>('C', cur.next);Если cur никуда не указывает, произойдет ошибка. Предусмотрим эту ситуацию:
if cur <> nil then
cur.next := new Node<char>('d', cur.next);Заметим также, что если cur указывает на последний элемент списка, ошибки не произойдет (фактически, будет произведена вставка в конец списка).
- Удаление элемента после текущего

cur.next := cur.next.next;Заметим, что текущий элемент — cur, должен не только не быть пустым, но и не быть последним в списке, т.к. происходят два разыменования: cur.next и cur.next.next. Для проверки этого факта можем воспользоваться утверждением:
Assert( (cur <> nil) and (cur.next <> nil) );
cur.next := cur.next.next;- Проход по списку

var cur := head;
while cur <> nil do
begin
writeln(cur.data);
cur := cur.next;
end;<xh4>Примеры использования</xh4>
Пример 1.
Дан файл целых чисел.
Записать все его элементы в линейный односвязный список.
var f: file of integer;
Assign(f, 'numbers.dat');
Reset(f);
var a: integer;
Read(f, a);
var head := new Node<integer>(a, nil);
var cur := head;
while not Eof(f) do
begin
read(f, a);
cur.next := new Node<integer>(a, nil);
cur := cur.next;
end;
Close(f);Пример 2.
Поиск элемента с заданным значением.
// x — искомый символ
var cur := head;
while (cur <> nil) and (cur.data <> x) do
cur := cur.next;
if cur = nil then
// не найдено
else
// cur — ссылка на искомый xДвусвязные линейные списки
<xh4>Введение</xh4> В отличие от односвязных линейных списков, двусвязные, помимо полей data и next, имеют поле prev (указатель на предыдущий элемент списка):
type
Node<T> = class
data: T;
prev, next: Node<T>;
constructor (d: T; p, n: Node<T>);
begin
data := d;
prev := p;
next := n;
end;
end;В случае двусвязного списка нам достаточно иметь ссылку на любой узел, тогда все остальные можно найти. Однако, для удобства, будем считать, что у нас есть две ссылки:
- head — на начало списка
- tail — на конец списка
<xh4>Стандартные операции с двусвязными линейными списками</xh4> Замечание. При выполнении любой операции нужно следить за возможными изменениями head и tail.
- Инициализация
head := nil;
tail := nil;- Добавление элемента в начало

Примечание. Если изначально список был пуст, после добавления элемента надо не забыть сделать tail указывающим на него.
head := new Node<T>(0, nil, head);
if head.next <> nil then
head.next.prev := head
else // если список был пуст
tail := head;- Добавление элемента в конец

tail := new Node<T>(2, tail, nil);
if tail.prev <> nil then
tail.prev.next := tail
else // если список был пуст
head := tail;- Удаление элемента из начала

head := head.next;
if head = nil then
tail := nil
else
head.prev := nil;- Удаление элемента из конца

tail := tail.prev;
if tail = nil then
head := nil
else
tail.next := nil;- Вставка элемента перед текущим

if cur = head then
// вставка в начало
else
begin
cur.prev := new Node<T>(3, cur.prev, cur);
cur.prev.prev.next := cur.prev;
end;- Вставка элемента после текущего

if cur = tail then
// вставка в конец
else
begin
cur.next := new Node<T>(3, cur, cur.next);
cur.next.next.prev := cur.next;
end;- Удаление текущего

if cur = head then
// удаление из начала
else if cur = tail then
// удаление из конца
else
begin
cur.prev.next := cur.next;
cur.next.prev := cur.prev;
cur := cur.next;
end;- Проход по списку
Проход по списку в прямом порядке аналогичен этой операции для односвязных списков.
Проход в обратном порядке можно организовать заменой:
- head на tail
- next на prev
<xh4>Двусвязный линейный список как класс</xh4>
Ясно, что удобно оформить все операции в виде подпрограмм. Но тогда каждый раз в качестве параметров надо передавать ссылки на начало и конец списка.
Создадим класс двусвязный линейный список, полями которого будут head и tail:
type
Node<T> = class
data: T;
prev, next: Node<T>;
constructor (d: T; p, n: Node<T>);
begin
data := d;
prev := p;
next := n;
end;
end;
DoubleLinkedList<T> = class
head, tail: Node<T>;
constructor;
begin
head := nil;
tail := nil;
end;
procedure AddFirst(d: T);
begin
head := new Node<T>(d, nil, head);
if head.next <> nil then
head.next.prev := head
else // если список был пуст
tail := head;
end;
procedure AddLast(d: T);
begin
tail := new Node<T>(d, tail, nil);
if tail.prev <> nil then
tail.prev.next := tail
else // если список был пуст
head := tail;
end;
procedure DeleteFirst;
begin
head := head.next;
if head = nil then
tail := nil
else
head.prev := nil;
end;
procedure DeleteLast;
begin
tail := tail.prev;
if tail = nil then
head := nil
else
tail.next := nil;
end;
procedure InsertBefore(cur: Node<T>; d: T);
begin
if cur = head then
AddFirst(d)
else
begin
cur.prev := new Node<T>(d, cur.prev, cur);
cur.prev.prev.next := cur.prev;
end;
end;
procedure InsertAfter(cur: Node<T>; d: T);
begin
if cur = tail then
AddLast(d)
else
begin
cur.next := new Node<T>(d, cur, cur.next);
cur.next.next.prev := cur.next;
end;
end;
function RemoveAt(cur: Node<T>): Node<T>;
begin
if cur = head then
begin
DeleteFirst;
Result:=head;
end
else if cur = tail then
begin
DeleteLast;
Result:=nil;
end
else if cur = tail then
begin
DeleteLast;
result := nil;
end
else
begin
cur.prev.next := cur.next;
cur.next.prev := cur.prev;
result := cur.next;
end;
end;
procedure Print;
begin
var cur := head;
while cur <> nil do
begin
writeln(cur.data);
cur := cur.next;
end;
end;
procedure PrintReverse;
begin
var cur := tail;
while cur <> nil do
begin
writeln(cur.data);
cur := cur.prev;
end;
end;
end;Пример.
Дан двусвязный линейный список с целыми значениями.
Удалить все его отрицательные элементы.
var list: DoublyLinkedList<integer>;
// создание списка
var cur := list.head;
while cur <> nil do
if cur.data < 0 then
cur := list.RemoveAt(cur)
else
cur := cur.next;